
控制大象的小老鼠

控制大象的小老鼠
撰文/陳儁翰
NLP語言模型如GPT-2或是BERT,雖然功能強大──任何人都可以從Github上下載,快速產生流暢、以假亂真的文字內容──但本質上都屬於文本預測系統(根據上下文推測下一個最有可能出現的字詞或句子),容易被有心人士操弄,產生帶有歧視或極端負面的文字。它們就像是力量強大的大象,如果開發者無法約束模型所生成的文字內容,能實際付諸應用的地方便會處處受限。來自Uber AI的研究員就找到了一隻可以用來控制大象的小老鼠。
屬性模型
這是一種隨插即用的框架,叫做Plug and Play Language Models(PPLM),可以讓研究人員對模型生成的文字有更大程度的控制。PPLM包含了一個屬性模型(attribute model),也就是當你輸入一段話,它可以告訴你這段話跟某個主題之間的相關性,比如:
\[ p(動物|我有一隻小毛驢)=0.2 \]
\[ p(科學|我有一隻小毛驢)=0.00001 \]
\[ p(政治|我有一隻小毛驢)=0.05 \]
說明「我有一隻小毛驢」這句話比較有可能出現在與「動物」這個主題相關的對話中,可能性高於「政治」或「科學」相關的對話。
條件語言模型
將屬性模型在PPLM框架下與語言模型(如GPT-2)結合,就變成了一個條件語言模型。根據貝氏定理,我們可以得到「特定主題的對話中出現一句子的機率」正比於「該句子出現在特定主題中的機率」與「該句機率」的乘積,也就是:
\[ p(句子|主題) \propto p(主題|句子) \cdot p(句子) \]
其中\( p(主題|句子) \)可由屬性模型得到,\( p(句子) \)和\( p(句子|主題) \)分別對應到語言模型與條件語言模型的輸出。
使用PPLM的好處在於,原有的語言模型本身並不需要再次訓練或微調,只要更新部分隱空間即可,以下簡單介紹要如何結合這兩個模型(以GPT-2為例):
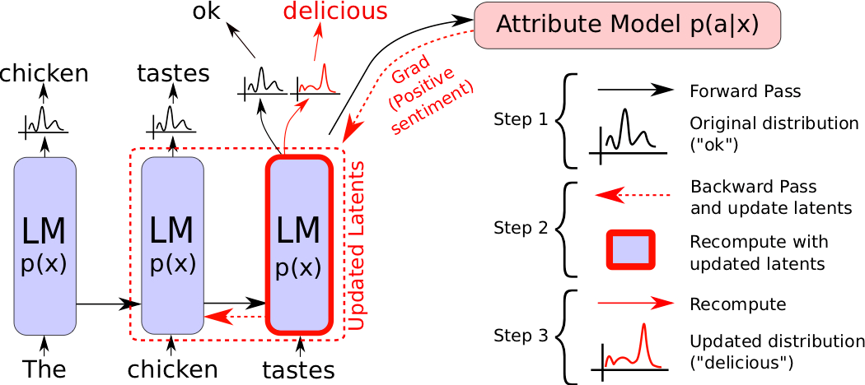
文字輸入為「這雞肉吃起來……」,語言模型原先的輸出為「雞肉吃起來普普通通」。我們希望能生成更正面的句子,於是透過屬性模型改變輸出語句的語氣,使得語言模型最終輸出「雞肉吃起來很美味」。(圖片來源:Dathathri et al 2019.)
- 文字輸入GPT-2模型,所產生的結果傳遞給屬性模型。
- 以屬性模型反向傳播的結果來更新GPT-2的隱空間參數。
- GPT-2再次產生新的輸出。
以上步驟可以重複數次。
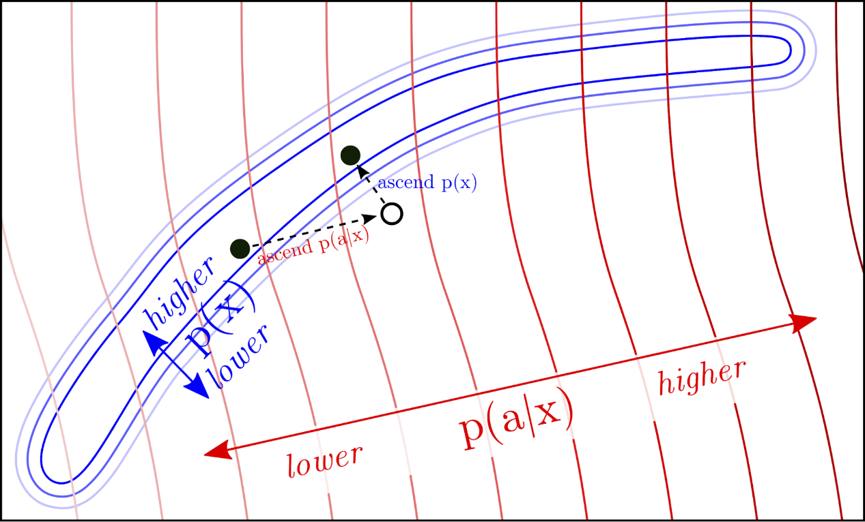
限制語言模型的更新只在值較高的藍色區域移動,使條件語言模型依然能產生通順的句子。(圖片來源:Dathathri et al 2019)
然而根據屬性模型反向傳播的結果來更新GSP-2的參數,變動幅度可能過大,這就像如果我們一味讓模型產生更正向的句子,而不加予限制的話,很可能會產生像是「很棒!很棒!非常棒!」這類空泛的回應。一個好的條件語言模型應該也要像一般的語言模型一樣,生成通順、符合語境的句子,所以我們可以透過限制更新前與更新後語言模型間的KL散度(Kullback-Leibler divergence),使得兩個模型的分布是接近的,如此便能產生既通順又與主題相關的句子。
Uber AI將PPLM模型與試用版開放在網路上,讓大家都有機會一試這個能操控大象的小老鼠。
參考資料
- S. Dathathri et al., “Plug and Play Language Models: A Simple Approach to Controlled Text Generation“, arXiv.org, 2019.
- E. Wallace, S. Feng, N. Kandpal, M. Gardner and S. Singh, “Universal Adversarial Triggers for Attacking and Analyzing NLP“, arXiv.org, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)
 前一篇文章
前一篇文章 下一篇文章
下一篇文章 我們一直都在學習—專訪林守德
我們一直都在學習—專訪林守德  自然語言處理的靈活應用家——專訪馬偉雲
自然語言處理的靈活應用家——專訪馬偉雲  手腕上的人工智慧
手腕上的人工智慧  牙牙學語新觀點(2/3)
牙牙學語新觀點(2/3)  誰來監管機器人?
誰來監管機器人?  iOS14變更隱私權政策 Apple與FB兩大科技巨頭的戰爭
iOS14變更隱私權政策 Apple與FB兩大科技巨頭的戰爭  「問題與答案」的人生曲線——專訪黃從仁
「問題與答案」的人生曲線——專訪黃從仁  物聯網「聽」指令
物聯網「聽」指令 

